简介 @
基础架构 @
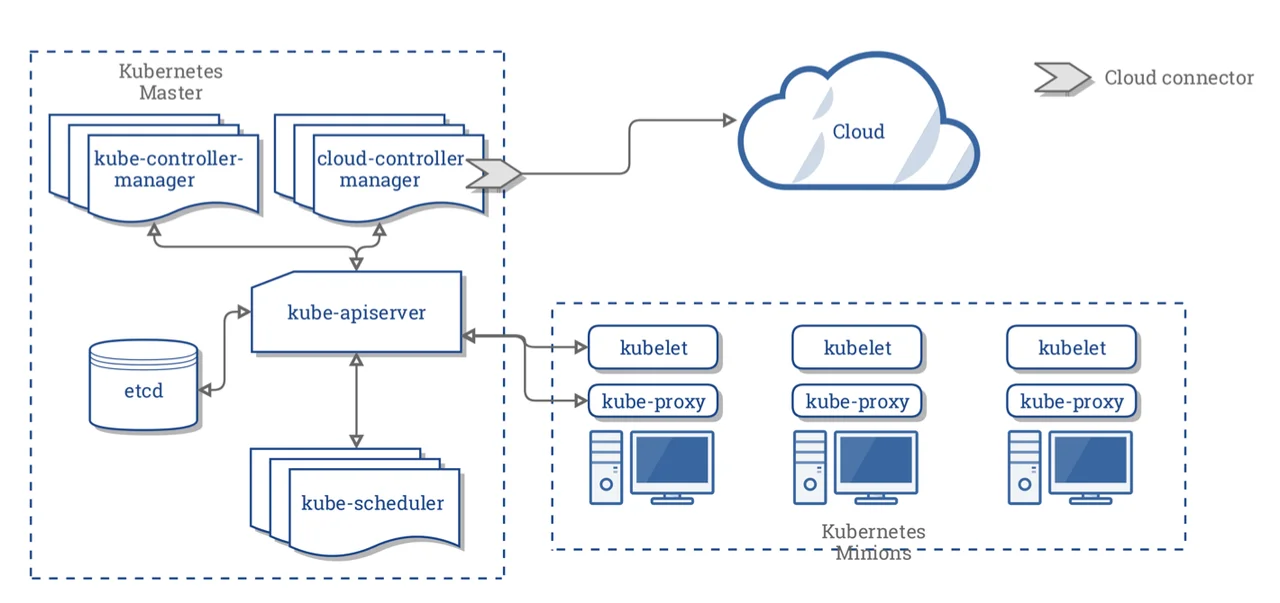
- Pod 是 Kubernetes 中管理和调度的最小工作单位,Pod 中可以包含多个容器。这些容器会共享 Pod 中的网络等资源
- Node 则是指一台服务器、虚拟机等,运行着一个完整的操作系统,提供了 CPU、内存等计算资源,一个 Node 可以部署多个 Pod
- Cluster 中运行着 N 个 Node(master/ worker), master 节点运行着 Kubernetes 系统组件,而 worker 节点负责运行用户的程序。所有节点都归 master 管,通过命令、API 的方式管理 Kubernetes 集群时,是通过发送命令或请求到 master 节点上的系统组件,然后控制整个集群
- 在一个集群中使用命名空间将不同的 Pod 隔离开来。但是 Kubernetes 中,不同 namespace 的 Pod 是可以相互访问的,它们不是完全隔离的。
基础组件 @
- Node Components 在 worker 节点中运行,为 Pod 提供 Kubernetes 环境
- Control Plane Components 用于对集群做出全局决策,部署在 master 节点上
- kube-apiserver 公开了 kubernates API,用于管理集群运行
- etcd 作为保存 kubernetes 所有集群数据的后台数据库,apiserver 操作结果也会存储到 etcd 中, 主要存储 k8s 状态、网络配置、其他持久化数据
- kube-scheduler 负责监视新创建的 pod,并将 pod 分配到节点上。
- kube-controller-manager 包括多个控制器
- Node Controller 节点控制器
- Job Controller 任务控制器
- Endpoints Controller 端点控制器
- Service Account & Token Controllers 服务帐户和令牌控制器
存放了 k8s 默认的控制平面组件的 YAML 文件
ls /etc/kubernetes/manifests/
.
├── etcd.yaml
├── kube-apiserver.yaml
├── kube-controller-manager.yaml
└── kube-scheduler.yaml
集群搭建 @
基础配置 @
# 准备三台机器,一台master 两台node
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
sed -i 's/enforcing/disabled' /etc/selinux/config
setenforce 0
# 关闭swap分区
swapoff -a # 临时关闭
vi /etc/fstab # 注释swap挂载
# 添加hosts映射
echo "
$(master_ip) $(master_domain)
$(node1_ip) $(node1_domain)
$(node2_ip) $(node2_domain)
" >> /etc/hosts
#更改主机名(3台主机)
hostnamectl set-hostname xxxxx
# 将桥接的IPv4流量传递到iptables链 net.ipv4.ip_forward如存在=0,修改为1即可
cat > /etc/sysctl.d/k8s.conf << EOF
net.ipv4.ip_forward = 1
net.ipv4.tcp_tw_recycle = 0
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
内核升级 @
# 查看内核版本
uname -a
# 安装epel源
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
yum install -y https://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm
# 查看内核版本并安装最新版本
yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
# 安装最新lt内核
yum --disablerepo='*' --enablerepo=elrepo-kernel install kernel-lt -y
# 查看系统grub内核启动列表
awk -F '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg
# 指定以新安装的编号0内核版本为默认启动内核
grub2-set-default 0
# 卸载旧版本内核
yum remove kernel -y
# 重启机器,以新内核启动
reboot
Docker 安装 @
yum install -y yum-utils
# 添加阿里源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装docker
yum install docker-ce-20.10.22
# 开机启动
systemctl start docker
systemctl enable docker
# 修改docker数据存放目录位置(默认:/var/lib/docker)
vim /etc/docker/daemon.json
{
"graph": "/data/docker",
"registry-mirrors": ["https://sk4dzqfg.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
# 重启docker
systemctl restart docker
##### 配置docker、kubeadm、kubelet
```bash
# 编辑配置文件
vim /etc/docker/daemon.json
{
"graph": "/data/docker",
"registry-mirrors": ["https://inahoo.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
systemctl restart docker
# 添加kubenates阿里yum软件源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# 安装kubeadm\kubelet\kubectl
yum install -y kubelet-1.23.6-0 kubeadm-1.23.6-0 kubectl-1.23.6-0
systemctl start kubelet
systemctl enable kubelet
Master 节点部署 @
kubeadm init --apiserver-advertise-address=192.168.7.211 \ # 一般为master节点ip
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.23.6 \
--service-cidr=10.140.0.0/16 \
--pod-network-cidr=10.240.0.0/16
# 非root执行
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
# root用户
export KUBECONFIG=/etc/kubernetes/admin.conf
Node 节点部署 @
kubeadm join 192.168.7.211:6443
--token 092qru.2z5e8vo3d9pcatgy
--discovery-token-ca-cert-hash
sha256:fe3445e3f251c04fabc89c75a03a9693c6f1389440e25b4426e5350f33cd22d3
安装网络插件(CNI) @
wget http://download.stisd.cn/k8s/kube-flannel.yml
# 修改net-conf.json下面的网段为上面pod-network-cidr的网段地址
sed -i 's/10.244.0.0/10.240.0.0/' kube-flannel.yml
kubectl apply -f kube-flannel.yml
# 查看pods节点状态
kubectl get pods -n kube-system
---
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: psp.flannel.unprivileged
annotations:
seccomp.security.alpha.kubernetes.io/allowedProfileNames: docker/default
seccomp.security.alpha.kubernetes.io/defaultProfileName: docker/default
apparmor.security.beta.kubernetes.io/allowedProfileNames: runtime/default
apparmor.security.beta.kubernetes.io/defaultProfileName: runtime/default
spec:
privileged: false
volumes:
- configMap
- secret
- emptyDir
- hostPath
allowedHostPaths:
- pathPrefix: "/etc/cni/net.d"
- pathPrefix: "/etc/kube-flannel"
- pathPrefix: "/run/flannel"
readOnlyRootFilesystem: false
# Users and groups
runAsUser:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
fsGroup:
rule: RunAsAny
# Privilege Escalation
allowPrivilegeEscalation: false
defaultAllowPrivilegeEscalation: false
# Capabilities
allowedCapabilities: ['NET_ADMIN', 'NET_RAW']
defaultAddCapabilities: []
requiredDropCapabilities: []
# Host namespaces
hostPID: false
hostIPC: false
hostNetwork: true
hostPorts:
- min: 0
max: 65535
# SELinux
seLinux:
# SELinux is unused in CaaSP
rule: 'RunAsAny'
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
rules:
- apiGroups: ['extensions']
resources: ['podsecuritypolicies']
verbs: ['use']
resourceNames: ['psp.flannel.unprivileged']
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flannel
subjects:
- kind: ServiceAccount
name: flannel
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: flannel
namespace: kube-system
---
kind: ConfigMap
apiVersion: v1
metadata:
name: kube-flannel-cfg
namespace: kube-system
labels:
tier: node
app: flannel
data:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: kube-flannel-ds
namespace: kube-system
labels:
tier: node
app: flannel
spec:
selector:
matchLabels:
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
hostNetwork: true
priorityClassName: system-node-critical
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni-plugin
#image: flannelcni/flannel-cni-plugin:v1.0.1 for ppc64le and mips64le (dockerhub limitations may apply)
image: rancher/mirrored-flannelcni-flannel-cni-plugin:v1.0.1
command:
- cp
args:
- -f
- /flannel
- /opt/cni/bin/flannel
volumeMounts:
- name: cni-plugin
mountPath: /opt/cni/bin
- name: install-cni
#image: flannelcni/flannel:v0.17.0 for ppc64le and mips64le (dockerhub limitations may apply)
image: rancher/mirrored-flannelcni-flannel:v0.17.0
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
#image: flannelcni/flannel:v0.17.0 for ppc64le and mips64le (dockerhub limitations may apply)
image: rancher/mirrored-flannelcni-flannel:v0.17.0
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: false
capabilities:
add: ["NET_ADMIN", "NET_RAW"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: EVENT_QUEUE_DEPTH
value: "5000"
volumeMounts:
- name: run
mountPath: /run/flannel
- name: flannel-cfg
mountPath: /etc/kube-flannel/
- name: xtables-lock
mountPath: /run/xtables.lock
volumes:
- name: run
hostPath:
path: /run/flannel
- name: cni-plugin
hostPath:
path: /opt/cni/bin
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
- name: xtables-lock
hostPath:
path: /run/xtables.lock
type: FileOrCreate
安装 metrics 组件 @
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 查看资源使用
kubectl top pod
集群删除 @
重新初始化 master 节点 @
# 删除所有节点
kubectl delete nodes xxxx
# 清空集群数据信息
kubeadm reset
# 查看pod情况
kubectl get pods -n kube-system -o wide
删除 kubeadm、kubectl、kubelet @
sudo yum remove -y kubeadm kubectl kubelet kubernetes-cni kube*
sudo yum autoremove -y
systemctl stop kubelet
systemctl disable kubelet
配置清理 @
rm -rf /etc/systemd/system/kubelet.service
rm -rf /etc/systemd/system/kube*
清理 kubernetes 配置 @
sudo rm -rf ~/.kube
sudo rm -rf /etc/kubernetes/
sudo rm -rf /var/lib/kube*
常用命令 @
kubectl 基础命令 @
# 查看pod,service,endpoints,secret,node等的状态
kubectl get pods/nodes/deployment/rs/pvc/pv (-o wide) # 详细信息
# 变更yaml文件内资源,可以是目录,没有则创建,有则变更
kubectl apply -f nginx.yaml
# 删除yaml文件内资源
kubeclt delete -f xxxx.yaml
# 查看事件
kubectl get events
# 查看资源状态
kubectl describe pod xxxxxx
# 查看pod日志
kubectl logs xxxxx
# 查看node节点或pod资源使用情况
kubectl top xxxx
# 进入pod内部
kubectl exec -it xxxx /bin/bash
# 查看集群信息
kubectl cluster-info
# 查看版本信息
kubectl version -o json
# 生成永久token
kubeadm token create --ttl 0
查看token
kubeadm token list
kubectl 自动补全 @
sudo yum install bash-completion -y
source <(kubectl completion bash)
echo "source <(kubectl completion bash)" >> $HOME/.bashrc
控制器 @
deployments @
Kubernetes Deployment 是一种 Pod 管理方式,它可以指挥 Kubernetes 如何创建和更新你部署的应用实例,创建 Deployment 后,Kubernetes 会将应用程序调度到集群中的各个节点上。
# 创建deployments
kubectl create deployment nginx --image=nginx:latest
# 查看deployments
kubectl get deployments -o wide
# 通过yaml部署
kubectl apply -f xxxxx.yaml
# 通过yaml删除
kubectl delete -f calico.yaml
# 编辑正在运行的deployment
kubectl edit deployment xxxxx
# 查看详情
kubectl describe deployment nginx
# 为deployment扩容pod数量
kubectl scale deployment nginx --replicas=3
# --dry-run=client 表示当前内容只是预览而不真正提交
kubectl create deployment testnginx --image=nginx:latest --dry-run=client
# 导出yaml文件
kubectl get deployment nginx -o yaml > mynginx.yaml
kubectl create deployment testnginx --image=nginx:latest --dry-run=client -o yaml
ReplicaSet @
#replicas 字段设置了维持多少个 Pod 实例
kubectl get deployment nginx -o yaml # 查看yaml文件
# 查看replicas
kubectl get replicaset/rs
# 创建时指定replicaset数量
kubectl create deployment nginx --image=nginx:latest --replicas=2
# 扩容pod数量
kubectl scale deployment nginx --replicas=3
DaemonSet @
DaemonSet可以确保一个节点只运行一个Pod副本。- 当新的
node加入集群时,会自动在这个node上部署一个Pod; - 当
node从集群中移开时,这个node上的Pod会被回收; - 如果
DaemontSet配置被删除,则也会删除所有由它创建的 Pod。 DaemonSet无视节点的排斥性,即节点可以排斥调度器在此节点上部署Pod,DaemonSet则会绕过调度器,强行部署。Kubernetes一些系统服务,也是DaemonSet部署模式。
kind: DaemontSet
Pod 升级、回滚 @
kubectl set image可以更新现有资源对象的容器镜像,对象包括Pod、Deployment、DaemonSet、Job、ReplicaSet- 可以通过
kubectl edit yaml的方式方式更新 Pod - 为了记录版本更新信息,我们需要在
kubectl create deployment、kubectl set image命令后面加上--record
kubectl set image deployment nginx nginx=nginx:1.20.0
kubectl set image deployment {deployment名称} {镜像名称}:={镜像名称}:{版本}
# 限制资源
kubectl set resources deployment nginx -c=nginx --limits=cpu=200m,memory=512Mi
# 查看 Pod 的上线状态
kubectl rollout status deployment nginx
# 查看 Pod 的上线记录
kubectl rollout history deployment nginx
- Deployment 可确保在更新时仅关闭一定数量的 Pod,默认情况下,它确保至少所需 Pods 75% 处于运行状态,也就是说正在被更新的 Pod 比例不超过 25%
# 回滚到上一个版本
kubectl rollout undo deployment nginx
# 回滚到指定版本
kubectl rollout undo deployment nginx --to-revision=2
# 暂停滚动更新
kubectl rollout pause deployment nginx
# 继续滚动更新
kubectl rollout resume deployment nginx
- Pod 的上线记录中,revision 记录的是部署记录,与 Pod 的镜像版本无关,每次更新版本或进行回滚等操作时, revision 会自动递增 1。
- 推荐每次执行滚动更新时都要带上这个参数
--record
Pod 缩放 @
水平缩放 @
基于 CPU 利用率自动扩缩 ReplicationController、Deployment、ReplicaSet 和 StatefulSet 中的 Pod 数量。Pod 自动扩缩不适用于无法扩缩的对象,比如 DaemonSet。
kubectl autoscale deployment nginx --min=10 --max=15 --cpu-percent=80
$$期望副本数 = ceil[当前副本数 * (当前指标 / 期望指标)]$$表示目标 CPU 使用率为
80%(期望指标),副本数量配置应该为 10 到 15 之间,CPU 是动态缩放 pod 的指标,会根据具体的 CPU 使用率计算副本数量,其计算公式如下。
比例缩放 @
比例缩放指的是在上线 Deployment 时,临时运行着应用程序的多个版本(共存),比例缩放是控制上线时多个 Pod 服务可用数量的方式
比例缩放是控制对象上线过程中,新的 Pod 创建速度和 旧的 Pod 销毁速度、 Pod 的可用程度,跟上线过程中新旧版本的 Pod 替换数量有关
# 新版本上线
kubectl set image deployment nginx nginx=nginx:latest
strategy:
rollingUpdate:
maxSurge: 3
maxUnavailable: 2
type: RollingUpdate
Label(标签) @
标签(Label)是附加到
Kubernetes对象上的键值对,在对象描述信息中以Labels字段保存
查看标签信息
kubectl get pods --show-labels
添加标签
kubectl label nodes <node-name> <label-key>=<label-value>
kubectl label pod {pod名称} <node-name> <label-key>=<label-value>
删除标签, 只需要在标签名字后面加上 -
kubectl label pod nginx-55495b586f-4hlzm disksize-
如果标签已经存在,需要覆盖
kubectl label pod nginx-55495b586f-4hlzm disksize=big --overwrite
NodeSelector @
通过给节点设置标签,然后在 Pod 的 YAML 文件中加上选择器,让 Pod 自动查找这类容量大的节点,并部署
# 获取节点标签
kubectl get nodes --show-labels
# 给节点加标签
kubectl label node instance-2 disksize=big
修改 yaml 文件, 这个 pod 只会在 disksize=big 的 Node 上运行
spec:
nodeSelector:
disksize: "big"
表达式是 disktype=ssd && disksize=big
nodeSelector:
disktype: ssd
disksize: big
条件查找 node
# 查询符合条件的node
kubectl get pods -l app=nginx
kubectl get pods -l app!=nginx
# 列出不包含某个标签的 Pod
kubectl get pods -l '!env'
kubectl get pods -l '!app'
# 同时包含两个标签的 Pod
kubectl get pods -l app,env
# 查看符合两个条件的节点
kubectl get nodes -l disktype=ssd,disksize!=big
部署集合选择方式
# 只获取disksize为big或medium的lable节点
kubectl get nodes -l disksize in (big,medium)
# 不在small的节点
kubectl get nodes -l disksize notin (small)
# 获取存在此lable的节点
kubectl get nodes -l exists disksize
# 下面写法也行
kubectl get pods -l 'app=nginx'
Selector @
由 Deployment 部署的每个 Pod 的名称都不同,所以不可能以 Pod 名称作为表示,何况 Pod 只是临时性的,所以会为每个 Pod 加上一个相同的 label,表示它们都是同一个 Deployment 创建的。
# spec.template 是定义所有 Pod 的模板
# template.metadata 可以为所有 Pod 设置一些元数据
template:
metadata:
labels:
app: nginx
selector 字段定义 Deployment 如何查找要管理的 Pods
matchLabels 里面的标签是集合运算的 in,Pod 只需要包含这些标签,就会被此 Deployment 管理
Selector 的符合运算 @
matchExpressions是 Pod 选择算符需求的列表。 有效的运算符包括In、NotIn、Exists和DoesNotExist。 来自matchLabels和matchExpressions的所有要求都按逻辑与的关系组合到一起 – 它们必须都满足才能匹配
matchExpressions:
- {key: tier, operator: In, values: [cache1,cache2]}
- {key: environment, operator: NotIn, values: [dev]}
- {Key: disksize, operator: Exists}
matchLabels 是由 {key,value} 对组成的映射。 matchLabels 映射中的单个 {key,value } 等同于 matchExpressions 的元素
matchLabels:
component: redis
两种结合使用
selector:
matchLabels:
component: redis
matchExpressions:
- {key: tier, operator: In, values: [cache]}
- {key: environment, operator: NotIn, values: [dev]}
Annotations @
annotations 由 key/value 组成,类似 label,但是 annotations 支持一些特殊字符,可以用作构建发布镜像时的信息、日志记录等
# 查看 annotations
kubectl describe services
# 添加 annotations, --overwrite指定覆盖
kubectl annotate service xxxxx -n xxxxxx description='my test'
# 删除 annotations
kubectl annotate service xxxxxxx description-
NodeAffinity @
节点亲和性, 可以让 Deployment 等对象部署 Pod 时选择合适的节点
requiredDuringSchedulingIgnoredDuringExecution硬需求,将 Pod 调度到一个节点必须满足的规则。preferredDuringSchedulingIgnoredDuringExecution。尽量满足,尝试执行但是不能保证偏好。
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
... ...
preferredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
... ...
# 反亲和性
AntiAffinity:
xxxxxxx
如果设置了多个 nodeSelectorTerms, 只需要满足其中一种表达式即可调度 Pod 到节点上, 官方文档如下
https://kubernetes.io/zh/docs/concepts/scheduling-eviction/assign-pod-node
Node taint、tolerations @
污点和容忍度节点污点:当节点添加一个污点后,除非 Pod 声明能够容忍这个污点,否则 Pod 不会被调度到这个 节点上如果节点一开始没有设置污点,然后部署了 Pod,后面节点设置了污点,节点可能会删除已部署的 Pod,这种行为称为驱逐节点污点(taint) 可以排斥一类特定的 Pod,而 容忍度(Tolerations)则表示能够容忍这个对象的污点。
# 添加污点
kubectl taint node [node] key=value:[effect]
# 更新污点或覆盖
kubectl taint node [node] key=value:[effect] --overwrite=true
# 查看节点的污点, jq (json 筛选工具)
kubectl get nodes instance-2 -o json | jq '.items[].spec.taints'
kubectl describe nodes xxxxx | grep Taints
# yaml文件中修改污点
apiVersion: v1
kind: Node
metadata:
...
...
spec:
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
系统会 尽量避免将 Pod 调度到存在其不能容忍污点的节点上, 但这不是强制的。Kubernetes 处理多个污点和容忍度的过程就像一个过滤器:从一个节点的所有污点开始遍历, 过滤掉那些 Pod 中存在与之相匹配的容忍度的污点。
# 污点的效果称为 effect
[
{
"effect": "NoSchedule",
"key": "key1",
"value": "value1"
}
]
NoSchedule:不能容忍此污点的 Pod 不会被调度到节点上;不会影响已存在的 pod。PreferNoSchedule:Kubernetes 会避免将不能容忍此污点的 Pod 安排到节点上。NoExecute:如果 Pod 已在节点上运行,则会将该 Pod 从节点中逐出;如果尚未在节点上运行,则不会将其调度到此节点上。
某些系统创建的 Pod 可以容忍所有
NoExecute和NoSchedule污点,因此不会被逐出 master 节点是不会被 Deployment 等分配 Pod 的,因为 master 有个污点,表面它只应该运行kube-system命名空间中的很多系统 Pod,用户 Pod 会被排斥部署到 master 节点上。
kubectl describe nodes master | grep Taints
# 查询所有节点的污点
kubectl describe nodes | grep Taints
Kubeenetes 还会在某些情况下,某种条件为真时,节点控制器会自动给节点添加一个污点。当前内置的污点包括
node.kubernetes.io/not-ready:节点未准备好。这相当于节点状态Ready的值为 “False"。node.kubernetes.io/unreachable:节点控制器访问不到节点. 这相当于节点状态Ready的值为 “Unknown"。node.kubernetes.io/out-of-disk:节点磁盘耗尽。node.kubernetes.io/memory-pressure:节点存在内存压力。node.kubernetes.io/disk-pressure:节点存在磁盘压力。node.kubernetes.io/network-unavailable:节点网络不可用。node.kubernetes.io/unschedulable: 节点不可调度。node.cloudprovider.kubernetes.io/uninitialized:如果 kubelet 启动时指定了一个 “外部” 云平台驱动, 它将给当前节点添加一个污点将其标志为不可用。在 cloud-controller-manager 的一个控制器初始化这个节点后,kubelet 将删除这个污点。
当节点上的资源不足时,会添加一个污点,排斥后续 Pod 在此 节点上部署,但不会驱逐已存在的 Pod。
kubeadm join 流程 @
在 kubeadm init 过程中,会生成 bootstrap token,node 节点可以安装 kubelet 和 kubeadm,执行 kubeadm join 加入到这个集群。
- node 上的 kubeadm 会发起一次“不安全模式”访问 kube-apiserver,从而拿到保存在 etcd 中的 cluster-info, 也就是我们在 kubeadm 中最后说到的 configmap, cluster-info 保存着 ca.crt 等 master 的重要数据,而 bootstrap token 则扮演这个过程中的安全验证角色。
- node 上的 kubelet 只要拿到 cluster-info 数据,那么之后就可以以“安全模式”连接到 apiserver 上去, 这样一个新的节点就加入到了集群
- 在执行 join 命令时,首先会对当前 node 环境进行检查,然后会携带 2 个重要的参数 discover-token-ca-cert-hash 和 token,进行身份验证
discover-token-ca-cert-hash @
用于 node 验证 master 身份,保证当前 node join 到正确的 master 中,执行 join 时,apiserver 会下发下发 ca.crt 公钥证书,这个证书数据会被 node 存放在/etc/kubernetes/pki 目录下面,然后 kubeadm 会用公钥证书的哈希值与–discover-token-ca-cert-hash 的值进行比对,确定是否为正确的 maste
通过openssl计算公钥哈希值
openssl x509 -in ca.crt -noout -pubkey |
openssl rsa -pubin -outform DER 2>/dev/null |
sha256sum | cut -d' ' -f1
token @
- 用于 master 验证 node 身份,要想在集群首次引导启动时进行 token 验证,必须在 kube-apiserver.yaml 中开启 enable-bootstrap-token-auth,一旦将此选项设置为 true,那么就允许 apiserver 在集群 init 的时候,开启 token 验证。
- token 分为 2 段, 前面一段是 token id,后面一段是 secret,当 kubeadm join 访问 apiserver 的时候,会在请求的 header 中携带这一个 token,apiserver 会根据这个 token 进行身份验证
- apiserver 会查询 kube-system 名称空间下是否存在 bootstrap-token 前缀的 secret
kubectl get secret -n kube-system | grep bootstrap-token
# apiserver会用这个查询到的secret和header中的token进行验证
# 查看 token-id 和 token-secret 字段的值
kubectl get secret bootstrap-token-oddhj0 -o yaml -n kube-system
# 进行base64解码
echo "xxxxxx" | base64 -d
# 将这2个解码后的数据进行组合,就是token
Helm 包管理 @
helm repo list # 查看当前配置的仓库地址
helm repo remove xxxx #删除仓库
# 添加几个常用的仓库,可自定义名字
helm repo add stable https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
helm repo add kaiyuanshe http://mirror.kaiyuanshe.cn/kubernetes/charts
helm repo add azure http://mirror.azure.cn/kubernetes/charts
helm repo add dandydev https://dandydeveloper.github.io/charts
helm repo add bitnami https://charts.bitnami.com/bitnami
# 搜索chart
helm search repo xxxx
# 拉取chart到本地
helm pull bitnami/redis-cluster --version 8.1.2
# 安装chart
helm install redis-cluster bitnami/redis-cluster <参数>
# 卸载
helm uninstall redis-cluster
# 查看chart信息
helm show readme <chart>
# 检查依赖和模版配置
helm lint <path>
# 打包应用
helm package <path>
# 更新库
helm update
# 只会渲染yaml模版内容不会部署
helm install --debug --dry-run goodly-guppy ./mychart
# 查看列表
helm list
kubectl delete 只是删除集群中的资源
helm uninstall 不仅删除 pod,也删除 helm 安装 chart 时创建的所有资源
其他命令 @
重命名 Roles @
# 节点为master节点为none的节点
kubectl label node <nodename> node-role.kubernetes.io/master=master
# 节点为slave节点
kubectl label node <nodename> node-role.kubernetes.io/worker=worker
错误排查 @
# 查看pod状态
kubectl get pods --all-namespaces
# 查看kubectl.service日志
journalctl -f -u kubectl.service
# 查看kubelet.service日志
journalctl -f -u kubelet.service
快速搭建 prometheus 集群 @
# 端口31969
helm install prometheus prometheus-operator
helm install grafana bitnami/grafana
快速搭建 rocketmq 集群 @
# 安装 RocketMQ Operator
git clone https://github.com/apache/rocketmq-operator.git
cd rocketmq-operator
sh install-operator.sh # 默认配置中namespace是default
kubectl get po | grep rocketmq-operator # 查看安装信息
# 构建用于 K8s 集群部署的 RocketMQ 5.0 镜像
cd images/namesrv/alpine/ && sh build-namesrv-image.sh 5.0.0
cd images/broker/alpine/ && sh build-broker-image.sh 5.0.0
rocketmq 分为三个部分, 安装顺序如下
- nameservice
- broker
- console
测试使用 HostPath 方式进行存储
在宿主机准备目录,官方提供了创建目录的脚本
rocketmq-operator/deploy/storage/hostpath/prepare-host-path.sh
# 部署nameservice
kubectl apply -f example/rocketmq_v1alpha1_nameservice_cr.yaml
# 部署service
kubectl apply -f rocketmq-operator/example/rocketmq_v1alpha1_cluster_service.yaml
# 部署broker
kubectl apply -f example/rocketmq_v1alpha1_broker_cr.yaml
# 部署console
kubectl apply -f rocketmq-operator/example/rocketmq_v1alpha1_console_cr.yaml