想象一下,我们有三台缓存服务器(编号0、1、2),需要存储3万个文件。如何让这些文件均匀分布,既能让每台服务器分摊压力,又能快速找到需要的文件呢?
传统方法的困境 @
最初的做法很直接:对文件标识(如“文件名+创建时间”)进行哈希计算,然后对服务器数量取模:
hash(文件标识) % N
这样就能确定文件应该存放在哪台服务器上。查找时重复这个计算,直奔目标服务器即可。
但这种简单方法有两个致命缺陷:
- 缓存雪崩风险:当服务器数量变化时(比如从3台变成4台),大部分缓存会同时失效,导致所有请求瞬间涌向后端数据库
- 大规模缓存迁移:几乎所有的文件都需要重新分配位置,系统开销巨大
一致性哈希的巧妙设计 @
一致性哈希算法通过一个精妙的环形结构解决了上述问题。
构建哈希环 @
算法将整个哈希值空间组织成一个虚拟的圆环,范围是0到2^32-1,就像钟表一样首尾相接。
工作流程如下:
- 节点定位:计算每个服务器的哈希值(基于名称、编号或IP地址),将它们放置在环上的对应位置
- 文件分配:计算每个文件的哈希值,同样放在环上,然后顺时针寻找遇到的第一个服务器节点,这就是该文件的归属地
- 哈希选择:通常使用crc32等高效哈希算法
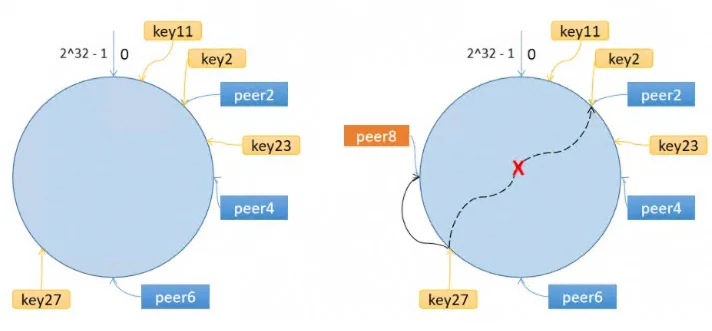
为什么这样更好? @
当服务器数量变化时,只有部分缓存会受到影响。比如服务器B下线,原本属于B的文件会顺延给服务器C,而属于A的文件完全不受影响。这种渐进式的调整避免了系统被瞬间压垮的风险。
隐藏的问题:哈希环偏斜 @
理想很丰满,现实可能很骨感。在实际应用中,我们可能会遇到这样的尴尬情况:
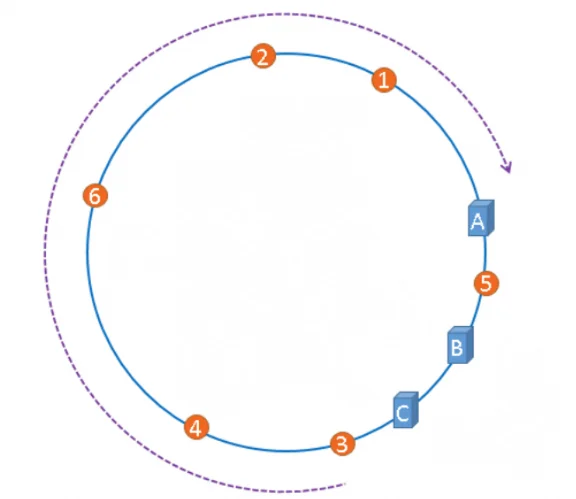
从图中可以看到,服务器A承载了大部分文件(1、2、3、4、6号),服务器B只缓存了5号文件,而服务器C竟然完全没有缓存!这种“旱的旱死,涝的涝死”的现象就是哈希环偏斜。
偏斜带来的后果:
- 资源利用极度不均衡
- 某个节点故障时,可能引发大规模缓存失效
- 系统稳定性受到严重威胁
优雅的解决方案:虚拟节点 @
为了解决偏斜问题,工程师们想出了“虚拟节点”这个巧妙的办法。
核心思想:为每个物理服务器创建多个“分身”,让这些虚拟节点均匀分布在哈希环上。
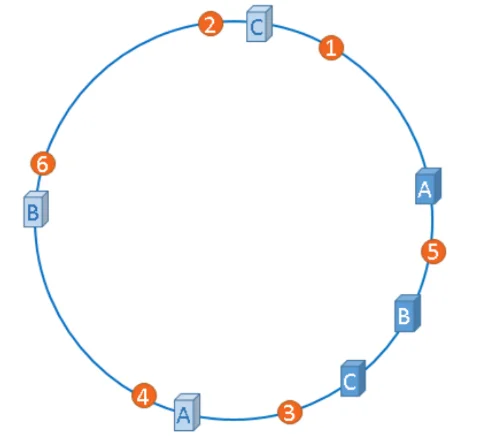
通过引入虚拟节点:
- 服务器A、B、C各自有了多个代表点
- 文件1、3归A,5、4归B,6、2归C——分布变得均衡合理
- 实现成本很低,只需要维护真实节点与虚拟节点的映射关系
总结 @
一致性哈希算法通过环形结构和虚拟节点技术,巧妙地解决了分布式缓存中的关键问题:
- 平滑扩展:节点增减时只有局部数据需要迁移
- 负载均衡:通过虚拟节点避免数据倾斜
- 系统稳定:有效防止缓存雪崩的发生
这种设计让分布式系统像精密的齿轮组一样,即使个别部件需要调整,整个机器仍能平稳运行,为我们构建高可用的互联网服务提供了坚实的技术基础。